



Imagine trying to read a 1,000-page fantasy novel, but your brain can only remember five pages at a time. To understand Chapter 20, you would have to flip back and re-read the entire book from page one.
That is exactly how Artificial Intelligence (AI) models like ChatGPT or Google Gemma feel when you give them massive prompts. To chat with you seamlessly, AI needs a mountain of high-speed computer memory (RAM) to remember the context of your conversation.
Because of the massive global AI boom, tech companies are buying up all the RAM they can get their hands on, causing prices to skyrocket. However, Google Research recently unveiled a revolutionary technology called TurboQuant that might just save the tech market—and your wallet.
Here is a breakdown of what TurboQuant is and how it could drive down RAM prices worldwide.

Part 1: What is TurboQuant?
To understand TurboQuant, we first need to look at how AI minds work. When an AI processes your text, it converts words into long lists of precise decimals called vectors (e.g., <0.12453, -0.89512, 0.45611>).
As your conversation grows longer, the AI stores these vectors in a temporary digital notepad called the KV Cache (Key-Value Cache). This cache lives inside the ultra-fast Video RAM (VRAM) or system RAM. The longer your chat, the massive this notepad becomes, eventually choking the computer’s memory.
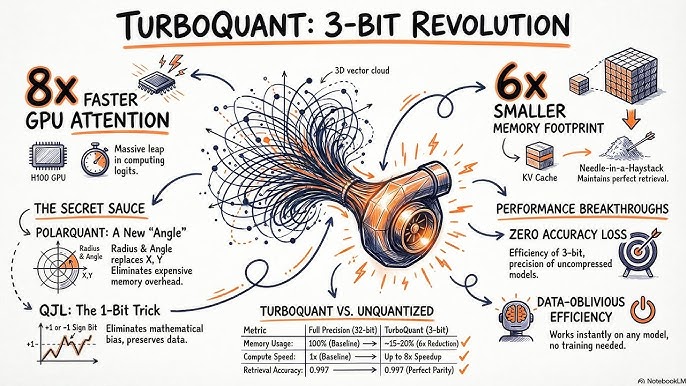
TurboQuant is an advanced data-compression algorithm designed to shrink this digital notepad by up to 6 times, without making the AI lose its “intelligence” or accuracy. It does this using a brilliant two-step math trick:
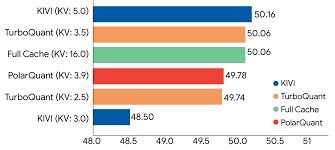
1. The “Rotation Trick” (PolarQuant)
In ordinary compression, software rounds off long decimals to short integers (like changing 5.874 to 6). However, AI data is usually full of erratic spikes—some numbers are tiny, and others are massive. Rounding them off normally causes huge errors.
TurboQuant solves this by mathematically “spinning” or rotating the vectors in abstract space. Think of it like taking a messy pile of clothes and spinning them in a blender until they form a perfectly smooth, uniform ball. Once the data is smooth and predictable, TurboQuant converts it into simplified angles (Polar Coordinates) and compresses it down to just 3 bits per value instead of the usual 16 or 32 bits.
2. The 1-Bit Compass (QJL Algorithm)
Even after the rotation, tiny errors can slip through. If the direction of the AI’s vectors shifts even slightly, the AI becomes confused and gives nonsensical answers.
TurboQuant reserves exactly 1 extra bit of memory to act as a mathematical compass (using the Quantized Johnson-Lindenstrauss or QJL algorithm). This single bit calculates the error and snaps the vectors back into their exact correct direction.
The result? The AI’s memory is compressed by 600%, but it remains 100% as smart as before!
Part 2: How TurboQuant Can Reduce RAM Prices in the Market
Right now, the world is facing a severe memory shortage. Because AI models require terabytes of fast RAM to run at scale, massive tech conglomerates are hoarding memory chips, driving up prices for everyday consumers building gaming PCs or buying laptops.
TurboQuant can break this supply chain bottleneck in three major ways:
1. Slashing Corporate Demand for Hardware
If a massive AI server cluster currently requires 6,000 Gigabytes of premium RAM to handle global user prompts, implementing TurboQuant drops that requirement down to just 1,000 Gigabytes. Tech companies will no longer need to panic-buy millions of physical hardware chips. When corporate demand slows down, the market supply stabilizes, causing prices to cool off.
2. Extending the Lifespan of Existing Hardware
Instead of forcing companies to constantly upgrade to newer, more expensive high-RAM servers, TurboQuant allows existing hardware to do six times more work. It optimizes the software so efficiently that an AI system which previously required enterprise-grade supercomputers can now comfortably run on standard, consumer-grade GPUs.
Without TurboQuant: High Memory Demand ➔ Scarcity ➔ Higher Market Prices
With TurboQuant: 6x Less Memory Needed ➔ Surplus ➔ Lower Market Prices
3. Boosting Manufacturing Efficiency
Building physical hardware is hard and expensive. TurboQuant shifts the heavy lifting from hardware manufacturing to clever software mathematics. Because a single computer chip can now manage workloads that previously required an entire rack of servers, the global manufacturing pressure on silicon, microchips, and RAM fabrics eases up dramatically.
Conclusion
TurboQuant proves that sometimes the solution to a massive engineering problem isn’t building bigger machines—it’s writing smarter math. By compressing AI memory by 6x with zero loss in quality, this technology is poised to reduce the tech industry’s desperate hunger for memory chips, paving the way for a more affordable hardware market for everyone.
To see a deep-dive visual demonstration of how modern algorithms compress data mathematically, you might find this TurboQuant: Redefining AI Efficiency Video highly informative.


{kind=link}